TEXT CONVERSION PROJECT:
Knight's American Mechanical Dictionary
Introduction
Scope of the job
Key in the text of Knight's American Mechanical Dictionary
at an accuracy rate of 1 error in 20,000 characters or better (99.995%
accuracy rate). Mark it up in SGML as instructed, so as to produce a
searchable textbase. Accuracy will be judged on the basis of samples (minimum: 5% of pages) proofread by University of Michigan staff.
Source of data
The item to be converted is a three-volume alphabetically arranged encyclopedia of
the mechanical arts, stored on our server as 400dpi gray-scale
image files. Vendor access to the data to be arranged (see last section, below).
Output data
The conversion product will consist of one or more (as convenient)
text files, marked up in valid SGML in accordance with our
proprietary dtd
and keying
instructions, and delivered via ftp or CD-ROM (preferably the former).
Files will be returned with a consistent system doctype declaration or
with this public doctype declaration:<!DOCTYPE KNIGHT PUBLIC "-//UMDLPS//DTD knight 1.0//EN">
Volume of data
The original consists of about 2800 images, one page per image. The
output text will probably amount to 10-15 MB of data.
Organization of the book
Overall high-level structure
<KNIGHT> (the entire work) should be subdivided into three <VOL>s
(with N attribute = "1" "2" or "3"). Each <VOL> will contain <FRONT>
matter preceding the <BODY>. The entries go in <BODY>; everything
else goes in <FRONT>.
The <BODY> of each volume (the run of entries) is subdivided into
alphabetical sections marked by a simple heading (<HEAD>) "A" "B" etc. Each alphabetical
section should be tagged as <PART>s of the <BODY> (with "N" attribute = "A" "B" etc.). If a section
is interrupted by the volume break, simply close the <PART> and reopen
it in where it resumes in the next volume. If a volume break interrupts an
entry, move the tail end of the entry forward so that the entry is complete
before the </PART> </BODY> </VOL>.
Primary organization by entry
As an encyclopedia in dictionary form, Knight's Dictionaryis arranged
primarily by the entry. The entry (<E>) therefore will be the chief
element of the markup. Each entry is divided into:
- One or more headwords (<HW>)
- A definition (<DEF>), containing chiefly:
- Paragraphs (<P>)
- Lists (<LIST>)
- Tables (<TABLE>)
- Illustrations (<FIGURE>)
- Field labels, e.g. "Nautical" "Bridge-building" "Carpentry" (<LABEL>)
- Cross references, e.g. "See SCREWDRIVER" (<REF>)
Typical simple entries
| Sample

|
Transcription
<E>
<HW>Abb.</HW>
<DEF>
<P><LABEL>Weaving.</LABEL> Yarn for the warp.</P>
</DEF></E>
<E>
<HW>A-bee`.</HW>
<DEF>
<P><LABEL>Fabric.</LABEL> A woven stuff of wool and cotton made in Aleppo.</P>
</DEF>
</E>
<E>
<HW>A-beam`.</HW>
<DEF>
<P>Opposite the center of the ship's side; as, "the wind is <I>abeam.</I>"</P>
</DEF>
</E>
<E>
<HW>Ab`e-run`ca-tor.</HW>
<DEF>
<P>A weeding-machine.</P>
</DEF>
</E>
<E>
<HW>A-but`ting-joint.</HW>
<DEF>
<P><LABEL>Carpentry.</LABEL> A joint in which the fibers of one piece
are perpendicular to those of the other.</P>
<P><LABEL>Machinery.</LABEL> A joint in which the pieces meet at a
right angle.</P>
</DEF>
</E>
|

|
<E>
<HW>A`ces.</HW>
<DEF>
<P><LABEL>Nautical.</LABEL> Hooks for
the chains.</P>
</DEF>
</E>
<E>
<HW>A-cet`i-fi-er.</HW>
<DEF>
<P>An apparatus for exposing cider, wort,
or other wash to the air to hasten the
acetification of the fermented liquor.
See <REF>GRADUATOR</REF>.</P>
</DEF>
</E>
<E>
<HW>Ac`e-tim`e-ter.</HW>
<DEF>
<P>See <REF>ACIDIMETER</REF>.</P>
</DEF>
</E>
<E>
<HW>Ac`e-tom`e-ter.</HW>
<DEF>
<P>A hydrometer suitably graduated for
ascertaining the strength of acetic acid
and vinegar.</P>
</DEF>
</E>
<E>
<HW>Ach`ro-mat`ic Con-dens`er.</HW>
<DEF>
<P>An achromatic lens or combination used to
concentrate rays upon an object in a microscope.
See <BIBL><I>Carpenter on the Microscope,</I>
pp. 117-119, ed. 1857.</BIBL></P>
</DEF>
</E>
|
Simple entry containing simple list.
|
Sample

|
Transcription
<E>
<HW>Ag`ate.</HW>
<DEF>
<P>1. <LABEL>Printing.</LABEL> A size of
type between Pearl and Nonpareil; called
Ruby in England.
<LIST>
<ITEM>Pearl.</ITEM>
<ITEM>Agate, or Ruby.</ITEM>
<ITEM>Nonpareil</ITEM>
</LIST></P>
<P>2. The draw-plate of the gold-wire
drawers; so called because the drilled eye
is an agate.</P>
<P>3. The pivotal cup of the compass-card.</P>
</DEF>
</E>
|
More elaborate lists follow the same pattern. Follow this link:
http://www.umich.edu/~pfs/knight/dox/lists.html
to see examples of lists with recommended transcriptions.
Simple entry containing simple table.
|
Sample.
|
Transcription.
<E>
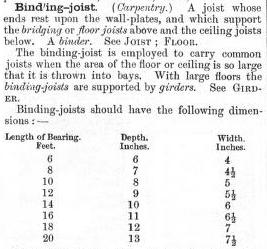
<HW>Bind`ing-joist.</HW>
<DEF>
<P><LABEL>Carpentry.</LABEL> A joist whose ends rest
upon the wall-plates, and which support the <I>bridging</I>
or <I>floor joists</I> and the ceiling joists below.
A <I>binder</I>. See <REF>JOIST</REF>; <REF>FLOOR</REF>.</P>
<P>The binding-joist is employed to carry common
joists when the area of the floor or ceiling is so
large that it is thrown into bays. With large floors
the <I>binding-joists</I> are supported by <I>girders.</I>
See <REF>GIRDER</REF>.</P>
<P>Binding-joists should have the following dimensions: —
<TABLE>
<ROW>
<CELL ROLE="label">Length of Bearing. Feet.</CELL>
<CELL ROLE="label">Depth. Inches.</CELL>
<CELL ROLE="label">Width. Inches.</CELL>
</ROW>
<ROW>
<CELL>6</CELL>
<CELL>6</CELL>
<CELL>4</CELL>
</ROW>
<ROW>
<CELL>8</CELL>
<CELL>7</CELL>
<CELL>4½</CELL>
</ROW>
<ROW>
<CELL>10</CELL>
<CELL>8</CELL>
<CELL>5</CELL>
</ROW>
<ROW>
<CELL>12</CELL>
<CELL>9</CELL>
<CELL>5½</CELL>
</ROW>
<ROW>
<CELL>14</CELL>
<CELL>10</CELL>
<CELL>6</CELL>
</ROW>
<ROW>
<CELL>16</CELL>
<CELL>11</CELL>
<CELL>6½</CELL>
</ROW>
<ROW>
<CELL>18</CELL>
<CELL>12</CELL>
<CELL>7</CELL>
</ROW>
<ROW>
<CELL>20</CELL>
<CELL>13</CELL>
<CELL>7½</CELL>
</ROW>
</TABLE>
</P>
</DEF>
</E>
|
More elaborate tables follow the same pattern. Follow this link:
http://www.umich.edu/~pfs/knight/dox/tables.html
to see an example of a more complex set of tables, with recommended transcription.
Aside from the basic sequence of HEADWORD-DEFINITION, the internal arrangement
of material in the entries can differ considerably. Labels always (?) appear
within paragraphs, but lists, tables, and illustrations can appear within paragraphs or between
them; lists can contain other lists; etc.
Other structural elements within entries
A number of entries contain block quotations, both in prose and in verse. These
should be tagged with <Q>; if the source is given, this should be tagged as
<BIBL>.
Entry containing block quotation in verse.
|
Sample.

|
Transcription.
<E>
<HW>Blank`et.</HW>
<DEF>
<P>1. <LABEL>Fabric.</LABEL> A coarse, heavy, open,
woolen fabric, adapted for bed covering, and usually
napped. It may be twilled or otherwise. A name applied
to any coarse woolen robe used as a wrapping.
<Q><L>Antiphanes, that witty man, says:</L>
<L>'Cooks come from Elis, pots from Argos,</L>
<L>Corinth blankets sends in barges.'</L>
<BIBL>ATHENAEUS (A.D. 220)</BIBL>
</Q></P>
<P>The <I>poncho</I> is a blanket with a hole
in the center for the head to go through. It is
worn by the South Americans, Mexicans, and Pueblo
Indians.</P>
<P>2. <LABEL>Printing.</LABEL> A piece of woolen,
felt, or prepared rubber, placed between the
inner and outer tympans, to form an elastic
interposit between the face of the type and the
descending platen.</P>
</DEF>
</E>
|
A very few entries contain a more elaborate internal structure, e.g. sets of tables,
where the sets themselves are organizational units with headings. For this (rare)
case of complex objects inserted within an entry, we have provided an <INSERT>
tag which may contain P LIST TABLE etc.,
or may be subdivided into <DIV1>s (and those if necessary into <DIV2>s).
Material not within entries
Each volume of the book contains some 'front matter' that does not
fall within entries: title page, preface, lists of plates, etc. This material
should be tagged as <DIV1>s of <FRONT>, e.g. the title page
as <DIV1 TYPE="title page">, the preface as <DIV1 TYPE="preface">,
but the DIVs themselves are internally tagged using ordinary <P> <LIST> <TABLE> etc. as
appropriate--no special tags for author or title, etc.
For sample capture of front matter, follow the following link:
http://www.umich.edu/~pfs/knight/dox/front.html
Page-breaks, page numbers, running headers
All information arising from the division of the book into
pages should be recorded as attributes of the <PB> tag.
The numerical designation of the image file should be captured in the
REF attribute; the printed page number (if any) should be captured
in the N attribute; and the running headers should be captured in the
"HEAD" attribute. On most pages, running headers will consist of
a pair of words or phrases, one over each column. Include both,
separated by a space.
The <PB> tag itself should be placed as near as possible
to the point at which the page actually 'breaks': that is, at the
point at which the reader would turn the page, insert the <PB>
tag for the new page.
When a new division of some kind begins on the new page, move the
<PB> tag forward as far as it needs to go in order for the
file to be valid. This means tucking it into the first content-bearing
element (e.g. E or DIV1).
Placement of tags. The rules are: (1) "pages always break at the top"; that is, <PB> tags will be inserted in
the text at the actual location of the page break, regardless of the location of the page number on the printed
page. (2) "Words cannot break at page breaks"; that is, if a hyphenated word straddles a page break, finish the
word and any attached punctuation, then insert the tag. And (3) "Divisions begin at page breaks; they don't end
there"; that is, if a structural break of some kind coincides with the page break (e.g., if a new section, paragraph,
etc., begins at the head of the new page), the <PB> tag should be tucked inside the opening tag for the new
division, NOT inside the closing tag for the old division.
Attribute values
Provide attribute values (e.g. the three attributes of the PB element; the N attribute of FIGURE PLATE VOL and PART) only when instructed to and
when there is specific information to supply. Do not supply values of this sort: TYPE="unknown" or
TYPE="unspecified".
Illustrations
The work includes both full-page plates and over 5000 individual
illustrations. Tag the full-page plates as <PLATE> and the
other illustrations as <FIGURE>. If a figure (or more likely
a plate) contains other numbered or captioned figures within it,
tag each subordinate illustration as a <FIGURE> tag within
the <PLATE> tag.
"Figure 45" ... Most of the illustrations
and plates are headed by a number (roman numeral for plates, arabic
numeral for figures). Capture this number as the N attribute of the
<FIGURE> or <PLATE> tag.
Captions and other text. Capture captions or caption-like material attached
to an illustration as a <HEAD> tag within the <FIGURE> (or
<PLATE>) tag. Other text that pertains to the whole illustration
(excluding, e.g., lettered references to various pieces and parts of
the picture) may be tagged using <P> within <FIGURE> (or within
<PLATE>). "See" references on a plate ("See truss, p. 43"), for example,
should be captured in a <P>.
Follow this link for a sample capture of a simple plate in context:
http://www.umich.edu/~pfs/knight/dox/plate.html
Entry with multiple illustrations
|
Sample

|
Transcription
<E>
<HW>A-but`ment.</HW>
<DEF>
<P>A fixed point or surface, affording a
relatively immovable object against which
a body <I>abuts</I> or presses while
resisting or moving in the contrary
direction. See <REF>PIER</REF>; <REF>SKEWBACK</REF>.</P>
<FIGURE N="4"><HEAD>Pier Abutment.</HEAD></FIGURE>
<P>1. <LABEL>Building.</LABEL> A structure
which receives the lateral thrust of an arch.
The abutment may be a pier or wing walls
forming a horizontal arch; or the arch may be
continued to a piled or hewn foundation,
which is then the <I>abutment</I>.</P>
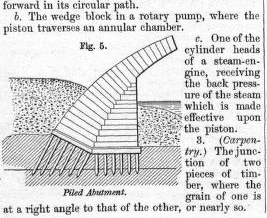
<P>2. <LABEL>Machinery.</LABEL> A solid
or stationary surface against which a fluid
reacts.</P>
<P>a. The wedge which lifts the piston
of one form of rotary steam-engine, and
which forms a surface for the steam to react
against as it presses the piston
forward in its circular path.</P>
<P>b. The wedge block in a rotary
pump, where the piston traverses an
annular chamber.</P>
<FIGURE N="5"><HEAD>Piled Abutment</HEAD></FIGURE>
<P>c. One of the cylinder heads of a
steam-engine, receiving the back pressure
of the steam which is made effective
upon the piston.</P>
<P>3. <LABEL>Carpentry.</LABEL> The
junction of two pieces of timber, where the
grain of one is at a right angle to that of
the other, or nearly so.</P>
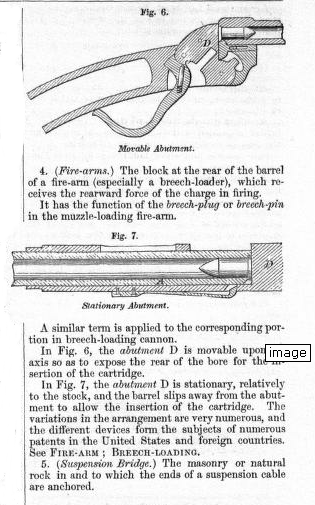
<FIGURE N="6"><HEAD>Movable Abutment.</HEAD></FIGURE>
<P>4. <LABEL>Fire-arms</LABEL> The block at
the rear of the barrel of a fire-arm (especially
a breech-loader), which receives the rearward
force of the charge in firing</P>
<P>It has the function of the <I>breech-plug</I>
or <I>breech-pin</I> in the muzzle-loading
fire-arm.</P>
<FIGURE N="7"><HEAD>Stationary Abutment</HEAD></FIGURE>
<P>A similar term is applied to the corresponding
portion in breech-loading cannon.</P>
<P>In Fig. 6, the <I>abutment</I> D is
movable its axis so as to expose the rear of
the bore for the insertion of the cartridge.</P>
<P>In Fig. 7, the <I>abutment</I> D is
stationary, relatively to the stock, and
the barrel slips away from the abutment
to allow the insertion of the cartridge.
The variations in this arrangement are very
numerous, and the different devices form
the subjects of numerous patents in the United
States and foreign countries.
See <REF>FIRE-ARM</REF>; <REF>BREECH-LOADING</REF>.</P>
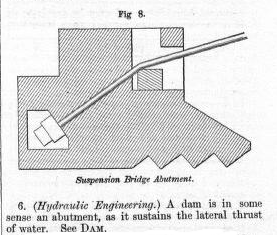
<P>5. <LABEL>Suspension Bridge.</LABEL> The
masonry or natural rock in and to which the
ends of a supension cable are anchored.</P>
<FIGURE N="8"><HEAD>Suspension Bridge Abutment</HEAD></FIGURE>
<P>6. <LABEL>Hydraulic Engineering.</LABEL>
A dam is in some sense an abutment, as it sustains
the lateral thrust of water. See <REF>DAM.</REF>.</P>
</DEF></E>
|
Another illustrated entry (excerpt)
|
Sample

|
Transcription.
<E><HW></HW><DEF>
<P>... 1864. This invention
consists in the employment of a pair
of suspending straps which pass over
the
<FIGURE N="19"><HEAD>Weber's Knapsack</HEAD></FIGURE>
shoulder in connection with another shorter
pair of straps attached to the top of the
knapsack near its center, and also a pair
of straps attached, one to each end of
the knapsack, for the purpose of varying
the position and shifting the weight
of the same when desirable.</P>
<P>WEBER, January 31, 1865. The frame
of the knapsack is capable of being
changed into a couch, and the cover forms
a shelter. The central section has jointed
and folding sides.</P>
<P>RUSH, March 25, 1862. The frame of
the knapsack is made of two parts, hinged
together
<FIGURE N="20"><HEAD>Rush's Knapsack.</HEAD></FIGURE>
At the thick end of one part are pivoted two arms,
which, when thrown out, rest upon the
edge of the knapsack, and serve to hold the
canvas for forming a bed.</P>
<P>FRODSHAM AND LEVETT, October 1, 1861.
This invention consists of an india-rubber
... </P>
</DEF></E>
|
Special problems: text sequence and illustration placement.
Text sequence. All pages should be captured in the order they
were intended to be read. In most cases this is straightforward: down the
lefthand column from top to bottom and then down the righthand column from top
to bottom. On some pages, however, especially where the page is interrupted
by a large illustration or table, the sequence is disrupted. It may,
for example, proceed halfway down the left column, then halfway down the
right, then back to the lower half of the left column, followed by the
lower half of the right. Follow the order that makes sense and that honors
the integrity of the entries.
Typical problem with text sequence
Illustration placement. Most illustrations appear within the
entry that they are intended to illustrate, and they should be recorded
so. But often the physical arrangement of the page dictated that the illustration appear
outside of the entry that it illustrated. In that case, if you can determine
which entry it really belongs to (using the information in the caption), move
the <FIGURE> tag so that it appears within the correct <E>ntry.
It is important that so far as possible, the figures illustrating a given
entry appear within that entry. (This applies to <FIGURE>s only: leave
<PLATE>s where they are.
For samples of these two typical problems, follow this link:
http://www.umich.edu/~pfs/knight/dox/probs.html.
Occasionally, illustrations appear after a line of text that ends with a hyphenated
word. Treat hyphenated words in this situation just as you when they appear at page
breaks. That is: words should not be broken by <FIGURE>s. If a
hyphenated word precedes an illustration, first finish
the word and any attached punctuation, and then insert the
FIGURE tag.
Character-level and word-level capture (italics, hyphens, character encoding, etc.)
Italics. Capture text in italics using the <I> tag. Omit <I> tag if you are already capturing the distinctiveness of the italicized portion in question using some structural tag, e.g. <LABEL>
Small caps. Capture text in small caps as if it were in regular caps.
End-of-line hyphens. If feasible, selectively remove end-of-line hyphens
where they were introduced simply in order to justify the line, leaving only the
hyphens that mark real compounds. If this is not judged feasible, record all
end-of-line hyphens as "|" (the keyboard 'pipe' character = HEX 7C) instead of "-", and reserve
"-" for hyphens that appear other than at the end of the line. (Any real example of
the vertical bar or 'pipe' character should in the latter case be captured with
the entity |).
Dashes. Capture dashes as —.
Quotation marks, apostrophes. Use the simple upright keyboard quotation-mark
and apostrophe characters (except as noted below under 'syllabification'. Do not attempt to distinguish between 'opening' and 'closing' quotation marks.
Non-ASCII characters. Capture non-ASCII characters using the standard
ISO character entities (ISOpub, ISOtech, ISOnum, ISOlat1, ISOlat2).
Unrecognized symbols. Unrecognized symbols should be captured as "#".
Individual non-roman letters. Individual letters in Greek should be captured using the
ISO Greek-1 entity set. E.g. (for the cases that I noticed):
- &ogr; (lower case omicron)
- &Agr; (upper case Alpha)
- &Bgr; (upper case Beta)
- &Ggr; (upper case Gamma)
Individual letters in other non-Roman alphabets or
writing systems (Hebrew, Chinese, Arabic, etc.)
should be recorded as unrecognized symbols with #.
Mathematical operators (+ - = etc.). Use the keyboard
character for = . Otherwise, capture as special characters using
standard character entities, e.g. as follows.
- ÷ = divide sign
- × = multiply sign
- + = plus sign
- ± = plus-or-minus sign
- √ = square-root (radical) sign
Illegibility. If you cannot read a letter, capture it as "$". If you cannot
read an entire word, capture it as "$word$"; any larger illegible section should be
marked captured as $span$.
Dollar signs. Since we use "$" to mark illegibilities, capture a literal
dollar sign using the entity $
Syllabification and stress in head-words. Headwords (HWs) are printed using
hyphens and vertical accent marks (') to indicate pronunciation. Capture the hyphens
as ordinary hyphens (-), but capture the accent marks using the 'back-tick' character
(`).
Punctuation placement and spacing. Normalize spacing around punctuation:
- no spaces before and one space after : ; . , ! ?
- no spaces around —
Font size. Changes in font size should be disregarded, except as a clue to structural divisions (e.g. a block quote).
Superscripts and subscripts. Capture subscripted and superscripted text by
placing the character ^ before each superscript character and ^^ before each
subscript character.
Braces (especially in tables). Braces are always difficult. As in EEBO, we'll say: interpret them
as best you can. Sometimes this will require entering text more
than once, e.g. if the brace means "this word applies to all these other
words," the easiest technique may be simply to apply the word to all
of the other words by entering it as many times; sometimes it
may require treating the single item as a head or label for a list containing
the grouped items; sometimes it may involve attaching a
ROWS or COLS attribute to a table <CELL>. Unfortunately, many variations are
possible.
Material to flag but not capture
Text in non-roman alphabet. Extended text (a word or more) in any non-Roman
alphabet, Greek included, should be captured
as <GAP DESC="foreign">.
Musical notation. Capture each piece of musical notation of any length as <GAP DESC="music">.
Mathematical formulas. Those that cannot be captured as simple text strings
(e.g. 2 × 3 = 6 or √4 = 2) should be captured as <GAP DESC="math">.
Block-level capture
Record paragraph breaks with the <P> tag.
Do not record text columns (except in tables) or column breaks
Do not record line breaks as such (except when the line breaks indicate a change from one item to
another in a <LIST> or <TABLE> of course).
Record page breaks with the <PB> tag (see above)
Do not record indentation; instead use the indentation as a cue to structure: e.g., the indent may
indicate a new paragraph (<P>), a block quote (<Q>), etc.
Text not to record at all
Handwritten notes or additions; and purely
decorative typographic markings should not be recorded at all.
Notes
Though I have not noticed any footnotes or marginal notes in this book, the dtd contains a
NOTE element that should be used to capture any that do occur. The PLACE attribute is used to capture
the location of the note (PLACE="foot" for footnotes; PLACE="marg" for marginal notes); the N attribute
is used to capture the footnote marker (e.g. "1" "*" etc.), which is otherwise to be omitted; and the note itself should be embedded
in the text at the point to which it refers (usually at the location indicated by the note marker).
Things missed.
Please bring to our notice any other situations that the instructions failed to
anticipate and we will work out a way to cope with them.
Individual tags: guide to use.
- BACK*
- Contains the back matter, if any, attached to each of the three volumes. Appears within: VOL
- BIBL*
- Contains bibliographical information (e.g. author or title or page number) associated with a quotation. Appears within Q P INSERT DIV1 DIV2 EPIGRAPH
- BODY*
- Contains the entries in each volume. Appears within: VOL
- CELL*
- Contains a data cell of a table (cp. HTML 'td' or 'th'). Multi-column or multi-row cells are designated using the COLS (cp. HTML 'COLSPAN') and ROWS (cp. HTML 'ROWSPAN') attributes. Cells used as headings for columns or rows are designated using the ROLE="label" attribute (cp. HTML 'TH' tag). Appears within: ROW.
- DEF
- Contains the definition section of an entry. Appears within: E
- DIV1*
- A division of the FRONT matter (or of an INSERTed text object). May appear within FRONT BACK INSERT.
- DIV2*
- A division of a DIV1. May appear within DIV1.
- E
- Contains an individual entry in the Dictionary. Appears within: PART
- FIGURE*
- Marks the location of an illustration occupying less than a full page. Contains captions (HEAD) and some other text, as above. Appears within: DEF, P, FIGURE, PLATE, HEAD, TRAILER, LIST, TABLE, CELL, ITEM
- FRONT*
- Contains the front matter attached to each of the three volumes. Appears within: VOL
- GAP*
- Empty tag marking the location of something that has not been captured, e.g. music, mathematical equations, or words in a non-roman script. In general, can appear wherever text data (PCDATA) can.
- HEAD*
- Contains a heading, e.g. of structural division (BODY PART DIV1 or DIV2), TABLE, LIST; or the caption of an illustration (FIGURE or PLATE). Appears within: FIGURE PLATE LIST TABLE DIV1 DIV2 INSERT BODY PART
- HW
- Contains the headword(s) of an entry (printed in bold). Phrases should be captured as a single HW, but two words separated by semicolon should be captured as two separate HWs.
One head word vs. multiple headwords
|
Sample

|
Transcription
<E>
<HW>A-but`ment Arch.</HW>
<DEF>
<P>An end arch of a bridge.</P>
</DEF>
</E>
<E>
<HW>A-can`tha-lus</HW>
<HW>A`can-tha`bo-lus</HW>
<DEF>
<P>An instrument for extracting thorns or
splinters from a wound.</P>
</DEF>
</E>
|
Appears within: E
- I
- Contains text in italics. Omit <I> tag if you are already capturing the distinctiveness of the italicized portion in question using some structural tag, e.g. <LABEL>. Appears: almost anywhere.
- INSERT
- Contains a textual object inserted in an entry too complex to be rendered using P TABLE or LIST. Appears within: DEF
- ITEM*
- Contains an item in a list. Indications of sequence (1. 2., etc.) should be recorded as plain text within the item. Appears within: LIST.
- KNIGHT
- Contains the entire work
- L*
- Contains a line of verse (poetry). Appears within: Q DEF LG INSERT
- LABEL
- Contains an indication of the field of industry to which a given term or definition belongs (printed in italics within parentheses). Omit the parentheses and capture just the text of the label. Appears within: DEF.
- LG*
- Contains an organized group of verse lines (poetic stanza). Appears within Q INSERT DIV1 DIV2
- LIST*
- Contains an ordered or unordered list of ITEMS (and an optional HEAD). Appears within: P DEF ITEM CELL DIV1 DIV2 INSERT etc.
- NOTE*
- Contains text of notes (especially footnotes and marginal notes). Appears in P L CELL ITEM HEAD etc.
- PART
- Contains an alphabetical section of entries. Appears within: BODY
- PB*
- Empty tag flagging page-break 'event'. Appears: almost anywhere, but not between entries, or between DIVs of the FRONT matter, or between FRONT and BODY.
- PLATE
- Marks the location of a full-page illustration or set of illustrations. Contains captions (HEAD) and some other text, as above. Appears within: FRONT BACK PART E DEF TABLE LIST
- Q*
- Contains a block quotation. Appears within: P DEF DIV1 DIV2 INSERT etc.
- REF*
- Contains a word or phrase intended as a cross-reference to another entry in the Dictionary. Restrict the contents of the tag to the word or phrase itself with following punctuation, i.e. See <REF>SCREWDRIVER.</REF>, not <REF>See SCREWDRIVER.</REF>. See under <REF>HAMMER.</REF>, note <REF>See under HAMMER.</REF>. Appears within: P CELL ITEM.
- ROW*
- Contains the row of a table. (cp. HTML 'TR' tag) Appears within: TABLE
- TABLE*
- Contains a table. Oriented by the row (like HTML). Contains ROWs (cp. HTML 'TRs') and an optional HEAD. Appears within: DEF P CELL ITEM DIV1 DIV2 INSERT etc.
- TRAILER*
- Same as HEAD, except that it appears at the end of section instead of the beginning.
- VOL
- Contains one volume of the entire work. Appears within: KNIGHT
A few other elements are included in the dtd, but are unlikely to see much (or any) use, except
perhaps in the preface: DATELINE*, DATE*, SALUTE*, SIGNED*, OPENER*, CLOSER*.
Elements marked with an asterisk above (*) are TEI tags and retain the meanings assigned them in TEI P3. (See
http://www.hti.umich.edu/t/tei/ for a quick TEI lookup by element name.). Most
of the other tags in the dtd are in fact shortcuts for TEI tags. Thus INSERT is essentially equivalent to the TEI
sequence Q TEXT BODY DIV0; VOL is equivalent to the TEI 'TEXT' tag; PART is equivalent to the TEI 'DIV1 TYPE="part"'; E is equivalent to the TEI 'DIV2 TYPE="entry"'; HW is equivalent to 'DIV3 TYPE="headword"'; DEF is equivalent to 'DIV3 TYPE="definition"'; and I is equivalent to 'HI REND="ital"'.
Misc.
Images of the book covers are included in the image set. Treat these as blank pages.
The samples supplied with this guide use invented values for the "REF" attribute of the PB tag. For the conversion project itself, we will supply id numbers for the images that should be referenced by this attribute.
To be arranged / subject to discussion
Three matters are left to be arranged, subject to discussion and negotiation with
the conversion vendor:
- The vendor's method of access to the image data remains to be worked out. It may be possible to
work directly from the on-line system, or we may be able to provide the images themselves in some form (electronic or print). In the meantime, the
page images can be viewed online by following THIS LINK and then following the link for image browse.
- As discussed above, we are uncertain whether the conversion vendor will be willing or able to resolve end-of-line hyphens. Though this is a relatively modern book, its usage with respect to the hyphenation of words
is unusual (in particular, it seems to hyphenate compounds much more than we would nowadays). The vendor is therefore offered the choice: (1) resolve EOL hyphens (i.e., selectively omit the hyphen, because it is used simply
in order to break a word at line end, or retain it, if it represents a 'real' hyphen, i.e., a hyphen that would be present even if the line did not end at that point). Or (2) capture all EOL hyphens with a distinctive character (|) and
leave us to resolve them.
- Also to do with hyphens, we expect as part of our post-processing to provide 'normalized' forms of all the headwords, forms that omit pronunciation and syllabification information. A vendor willing and able to
perform this step, however, is welcome to include it in their proposal. An attribute has
been included on the HW element (NORM) designed for this purpose. The difficulty arises again from
the use of hyphens, since the headwords as printed do not distinguish between hyphens used to
separate elements of compounds (which we would want to retain) and hyphens used to separate
syllables (which we would want to remove). Here are some sample headword elements
with the attribute included:
- <HW NORM="abb">Abb.</HW>
- <HW NORM="abeam">A-beam`.</HW>
- <HW NORM="abee">A-bee`.</HW>
- <HW NORM="aberuncator">Ab`e-run`ca-tor.</HW>
- <HW NORM="abutment arch">A-but`ment Arch.</HW>
- <HW NORM="abutment">A-but`ment.</HW>
- <HW NORM="abutting-joint">A-but`ting-joint.</HW>
- <HW NORM="acanthabolus">A`can-tha`bo-lus</HW>
- <HW NORM="acanthalus">A-can`tha-lus</HW>
- <HW NORM="aces">A`ces.</HW>
- <HW NORM="acetifier">A-cet`i-fi-er.</HW>
- <HW NORM="acetimeter">Ac`e-tim`e-ter.</HW>
- <HW NORM="acetometer">Ac`e-tom`e-ter.</HW>
- <HW NORM="achromatic condenser">Ach`ro-mat`ic Con-dens`er.</HW>
- <HW NORM="agate">Ag`ate.</HW>
- <HW NORM="agitator">Ag`i-ta`tor.</HW>
- <HW NORM="bevel plumb-rule">Bev`el Plumb-rule.</HW>
- <HW NORM="bevel scroll-saw">Bev`el Scroll-saw.</HW>
- <HW NORM="beveling-machine">Bev`el-ing-ma-chine`.</HW>
- <HW NORM="bevel-square">Bev`el-square.</HW>
- <HW NORM="bevel-tool">Bev`el-tool.</HW>
- <HW NORM="binding-joist">Bind`ing-joist.</HW>
- <HW NORM="binnacle">Bin`na-cle.</HW>
- <HW NORM="binocle">Bin`o-cle</HW>
- <HW NORM="binocular eyepiece">Bi-noc`u-lar Eye-piece</HW>
- <HW NORM="blade">Blade.</HW>
- <HW NORM="blanket">Blank`et.</HW>
- <HW NORM="medallion">Me-dal`lion.</HW>
- <HW NORM="medal-machine">Med`al-ma-chine`.</HW>
- <HW NORM="medicator">Med`i-cat-or.</HW>
- <HW NORM="medicinal bath">Me-dic`i-nal Bath.</HW>
- <HW NORM="medicinal cup">Me-dic`i-nal Cup.</HW>
- <HW NORM="medicine-spoon">Med`i-cine-spoon.</HW>
- <HW NORM="medium">Me`di-um.</HW>
- <HW NORM="medley">Med`ley.</HW>
- <HW NORM="meerschaum">Meer`schaum.</HW>
- <HW NORM="shoe-sewing machine">Shoe-sew`ing Ma-chine`.</HW>
- <HW NORM="shoe-shave">Shoe-shave.</HW>
- <HW NORM="shoe-sole">Shoe-sole.</HW>