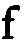CORPUS OF MIDDLE ENGLISH (CME)
Keying/Coding Specifications, draft 1.2
June 2000
Contents
- Introduction
- Keying/Coding Guidelines
- Material to record as literal text
- Material not to record at all
- Material to record as attribute values
- Recording formatting and layout
- Recording the apparatus
- Recording the text
- Characters
- Appendix 1: sample extracts illustrating the Guidelines
- Appendix 2: sample pages
- Appendix 3:
vendor.dtd
Introduction
Source data
The material to be keyed is taken from books (out-of-copyright editions of Middle English texts), and will be sent
to the data conversion firm on CD in the form of 600 dpi bitonal tiff files (one file per page). Pages that need to be
considered in pairs (because of text spread across a page opening) will be noted as such in the book-by-book coding
instructions (described below), though *all* the books may
potentially include run-on notes and similar text that requires consideration of more than one page at a time.
Files will be sequentially numbered within the item. I.e., the files for each book will start at "00000001.tif"
and go on from there.
Files will be arranged in directories, one directory for each item; the name of the directory will be the ID number assigned to the book. (see
http://www-personal.umich.edu/~pfs/med/cmeitems.html
for a list of books in process, with their id numbers).
Not all pages will be keyed. The pages to be keyed will be indicated both in the book-by-book coding instructions and on a spreadsheet printout that accompanies the CD-ROM.
Target data
The data-conversion vendor will return keyed and coded text files transcribed from the image files.
Transcriptional accuracy will be 99.995% or better (error rate of 1 character/byte in 20,000). We will test and if
necessary reject data by the book (volume), not by the shipment.
Coding will be valid SGML, validated against the supplied "vendor.dtd" or a true subset thereof. Vendor.dtd is an
extract from TEI and uses TEI semantics.
Quantity of data
Data will be sent on CDs, approximately 15-20 books per shipment
Total quantity will depend on the cost and speed of conversion. The budget is limited and must be 'spent down'
within the fiscal year. When we run out of time or money, we stop. If we can avoid both deadlines, assuming an approx.
cost of $1/1000 output characters, total output data should be in the range of 60-75MB. Estimated total books: 75+.
Keying/coding guidelines
NOTE: We recognize the need for consistency, and the expense entailed in changing instructions and procedures
midstream; such changes will certainly be minimized. Nevertheless, there is considerable variety in the source
material and minor special instructions may be required for some books, or some portions of books, in some cases
overriding the instructions given below. See the book-by-book coding instructions (posted at
http://www-personal.umich.edu/~pfs/med/mec.html#cme).
1. Material to record as literal text
| 1.1 | All of the books contain two chief kinds of content that we wish to preserve:
(1) the Middle English text(s); and (2) the editorial apparatus, which may appear as marginal notes, footnotes,
endnotes, or in other forms. Anything that falls into one of these categories or the other should be recorded. In most
cases this will mean all words on the page, from top to bottom, left to right.
TEXT. The Middle English text and its structures should be encoded using mostly the following structural
elements:
<DIV1> Division of the text.
<DIV2> Subdivision of the text.
<DIV3> Subdivision of the subdivision [etc., up to DIV7 as needed].
<HEAD> Heading
<P> Paragraph (for prose)
<LG> Line group (for verse)
<L> Line (for verse)
APPARATUS. Most editorial apparatus should be embedded within the text and should be tagged as <
NOTE> -- then within that with <P>, <LG>, and <L> as above, depending on whether it contains
verse or prose (or both), as well as with other structural elements (e.g. <LIST>) as needed.
Lines of verse quoted within a note, along with other matter, should normally be embedded as a quote
(<Q>) within the body of the <NOTE>.
Some editorial apparatus (e.g. tables of contents, some endnotes) will be treated separately as front matter or
back matter, as the case may be. But most such material--introductions, prefaces, indexes, glossaries, etc., will
be excluded from keying, and will consequently be excluded from the page images sent out from here. Title pages are
front matter that will usually be included.
Don't confuse "text" (meaning the edited Middle English work) with the <TEXT> tag (which is the high-
level tag element that includes the whole book).
<TEXT>
<FRONT>...</FRONT>
<BODY>....(ME text)....</BODY>
<BACK>....</BACK>
</TEXT>
|
| 1.2 | Some books may include a third type of content that we wish to record: (3)
scribal apparatus--notes or additions added in the margins or between the lines of the original manuscript. Since
it is not feasible to provide criteria sufficient to distinguish this from the text proper, or from editorial
apparatus--depending on how it is presented in the book--this type of content should be treated the same as whichever
it most resembles. I.e., if it printed as if it were marginal notes, treat it the same as editorial marginal notes; if
it is printed as if part of the text, treat it as part of the text. |
| 1.3 | Running parallel texts, displayed in a multi-column, multi-row, or
facing-page arrangement, or some combination thereof, need to be treated as separate texts, each one recorded until
its end and not restarted on each page. Editorial apparatus relating to one of the texts on a page needs to be
embedded in that text, not in any of the others. Some specific parallel texts, in some particular books, may be
excluded on a case-by-case basis. If a single heading applies to multiple parallel texts, it may be rekeyed at the
head of each text. A suggested <DIV> structure for handling such parallel texts will be included with the
shipment (see below).
In particular, partial or fragmentary parallel texts will normally be broken primarily at the
chapter or section level (<DIV1>), then into parallel versions of that chapter (<DIV2>) when necessary.
But full parallel texts will normally be broken primarily into versions first (<DIV1>), then each version
into its chapters (<DIV2>).
|
| 1.4 | All material should be recorded in the form in which it appears in the book:
do not attempt to correct spelling or typographic errors. |
2. Material not to record at all
- Running headers and footers.
- Catchwords and quire signatures.
- All other text that is simply an artifact of the printing process. For example, some books occasionally print the
author and title of the book in small type at the bottom of a page; some journals print the journal name and issue
number or date at the bottom of some pages: ignore these.
- Handwritten notes or other handwritten material.
- Text within illustrations (except captions)--rare.
- Separator lines and similar typographic flourishes.
- Most formatting. See below.
- Running summaries in modern English (not always readily distinguishable from notes or headings; if uncertain,
treat as note).
3. Material to record as attribute values
In general, use attributes only when there is specific information to put in them, and the guidelines specifically
call for its use. Do not, for example, record attributes of the sort 'TYPE="unknown"'
| 3.1 | Milestone information
Record most 'milestone' information (page numbers; folio, leaf, or column numbers of the source manuscript;
alternative page numbers derived from some other edition; etc.) as the value of the "n" attribute of the appropriate
milestone element, regardless of how they originally appear (e.g. in footnotes, in marginal notes, or in brackets
within the text). This requirement overrides the directions belonging to the type of structure in which the
information appears. That is, if milestone information appears in a footnote, treat it as milestone information, not
as a footnote; if it appears within the text, treat it as milestone information, not as text; etc.
The chief milestone elements are:
- <PB> page break in the physical book. Record a page break even if the page is unnumbered. If the
page is numbered, record the simple number as the value of the "N" attribute. Ignore any typographic elements used to
set off the page number. E.g. -2-, {p. 2}, and PAGE 2 should all be recorded as <PB N="2">.
Roman numerals should be retained: record (ii) as <PB N="ii">.
If a page break occurs in the middle of word, defer the page break till the word is completed, thus:
Cuthbert
<PB N="4">
came
not:
Cuth-<PB N="4">
bert came
- <MILESTONE> 'milestone.' Used:
(a) For folio references. Use this tag chiefly to record information about the original manuscript: folio
(or leaf) number, column number, or page number. Example: <MILESTONE UNIT="folio" N="3b">. Put the milestone
tag as close as possible to the location of the actual milestone: if the information appears alongside a line, place
the tag after the end of the line; if its exact location is flagged with an asterisk or footnote-type reference
number within the text, replace the flag with the milestone tag.
Folio (or leaf; sometimes page) references are important because they connect the edited text to its source
manuscript. They can appear in a variety of forms, often combined with a designation distinguising the front
(recto) of the leaf from the back (verso, dorso), and sometimes also giving the column number, if the text was
originally written with more than one column to the page. Typical forms include:
| meaning: "the back of leaf 4" | meaning:"the front
of leaf 4" |
|---|
| fol.4 | fol.4 |
| fol.4b | fol.4a |
| f.4v | f.4r |
| f.4 dorso | |
| folio 4 back, col.2 | folio 4 front, col.2 |
| lf.4b | lf.4a |
| lf.4 verso | lf.4 recto |
| leaf 4(b) | leaf 4(a) |
| leaf 4 b | leaf 4 a |
| 4b MS | 4a MS |
| 4v | 4r |
| RECORD AS: |
|---|
| N="4b" | N="4a" |
When recording the "N" value, collapse "4 dorso," "4 verso," "4v", and "4 back" into "4b"; collapse "4 recto,"
"4 front," "4r," and (if contrasted with 4b) even "4" into "4a". If there is no reference to front and back ("4"), use just the number ("4"). If the
book says "lf., leaf, f., fol., folio," etc., specify the unit as "folio"; if the numbers include any of the
front/back designations ("front", "back", "bk", "r", "v") assume that the unit is folio; if no unit is specified
and no front/back designator is used, do not supply a value for "unit". If the book specifies a column number as
well as a folio number, attach the column number to the folio number separated by a colon: record "fol.4v col.2"
as <MILESTONE UNIT="folio" N="4b:2">. Occasionally, only the column number appears, or only the designation
for front (recto) or back (verso) appears, with the actual folio number left to be inferred from a previous
reference, like this:
fol.4r, col.1
col.2
fol.4v, col.1
col.2
If possible, supply the implied information; otherwise, just leave the missing portion of the value blank. I.e.
record these as
<MILESTONE UNIT="folio" N="4a:1">
<MILESTONE UNIT="folio" N=":2">
<MILESTONE UNIT="folio" N="4b:1">
<MILESTONE UNIT="folio" N=":2">
(b) For manuscript page references Some manuscripts are paginated, rather than foliated, in which case
the reference will look like any other page number: p.4 (etc.). One manuscript (that of the Ormulum) is divided
only by column, in which case expect to see "col.4" (etc.). The former should be tagged as <MILESTONE UNIT="p"
N="4">; the latter as <MILESTONE UNIT="col" N="4">.
(c) For alternative numerations. If the book contains some other running numeration system alongside folio
or page references, use the milestone element to record it, and use its form, recorded with the "rend" attribute, to
distinguish it from folio references or other milestones. There is no need to interpret its meaning or decide on its
"unit" value. For example, if a book contains an unexplained sequential number in brackets in its margins, as well
as folio numbers marked with "f.", record the latter as <MILESTONE UNIT="folio" N=""> and the former as <
MILESTONE REND="margin" N="">; if it contains an explained series of numbers in the margins, use the explanation
as the "REND" value: if an edition, for example, contains a series of sequential references in the margin that look
like this: [Turnbull ed., p. 43], record them as milestones like this: <MILESTONE REND="turnbull" UNIT="p" N=
"43">.
|
| 3.2 | Structural enumerations
Numbers attached to various pieces of the document structure (line numbers; stanza numbers; chapter numbers, etc.)
should be recorded as the value of the "N" attribute of the appropriate structural element. If the number appears
without additional text, it may usually be recorded simply as an attribute and removed from the text; if it is
accompanied by additional material, the whole should usually be treated as a heading (<HEAD>). The most commonly
numbered elements include:
-
<L> line of verse. Record a line even if the line is unnumbered. If it is numbered, record the line
number as the value of the "N" attribute of the <L> element. Ignore typographic elements used to set off the
line number. E.g. 2345 and [2345] should both be recorded as <L N="2345">. Place the tag at the beginning of
the verse line, regardless of whether the line number appears to the right or to the left of the line.
-
Lines should be recorded (with <L>) only for poetry, not for prose, even if the edition of the prose text
supplies line numbers.
- If it is not clear whether it is verse or prose, follow specific instructions for that text, or (failing
that) treat as verse.
- If a single number on the page applies to the lines of two separate (parallel) texts, enter the line number
in both texts.
- Verse lines carried over to next line should be treated as one line, not two partial ones. E.g., record this:
And hend the tymber that fel thar
[to
like this:
<L>And hend the tymber that fel thar to</L>
- If bits of prose interrupt an otherwise verse text, judgment is called for:
(1) The prose may serve as a heading to a section of verse, in which case it should be tagged as <
HEAD>.
(2) The prose may be lineated continously with the verse, in which case treat it as verse.
(3) The prose may *not* be lineated continuously with the verse, in which case treat it as prose.
- Blank lines in verse may serve:
(1) to divide sections, in which case either a <LG> or a <DIV1> (<DIV2>, etc.) tag is
required; or
(2) to indicate lines that are in some sense lacking, in which case use an empty <L> tag for each
blank line. Use the lineation scheme to learn how many blank lines to include; or
(3) to allow parallel texts to line up next to each other, in which case ignore the white space completely.
In case (2) the blank lines are numbered; in case (3) they are not; that is the way to distinguish them.
- If the text contains alternative simultaneous lineations, use what appears to be the main one, and treat the
other as a milestone element (see above).
- <LG> line group or stanza in verse.
Record a stanza break even if the stanza is unnumbered. If the stanza is numbered, record the stanza number as
the value of the "N" attribute of the <LG> element. Ignore typographic elements used to set off the number.
E.g. 4 and (4) should both be recorded as <LG N="4">. If there is more information at the head of the stanza
(aside from the number), it qualifies as a heading <HEAD> and the entire heading should be preserved; if not,
the number may be removed from the text and preserved only as an attribute.
- <DIV1><DIV2> etc. Subdivisions in the text other than lines and stanzas: sections, chapters,
documents, poems, tracts, etc. Record the number BOTH as the value of the "N" attribute of the appropriate <
DIV> tag AND (together with any accompanying text) as a <HEAD> for the division in question. If the DIV is
clearly identified--either in the book or in the instructions--as belonging to a particular type (e.g., "chapter"),
record that with the 'type' attribute; if not, omit the attribute entirely.
If paragraphs are numbered (that is, if the lowest division consists of nothing but single
paragraphs, with no internal structure and no headings), use the "N" attribute of the <P> tag itself
instead of creating tiny <DIV>s. In this cases, the number may be discarded from the text proper and
preserved only as an attribute.
|
4. Formatting and layout
In general, do not attempt to record the physical appearance of the page (centering, extra spaces, justification,
type face, type size, etc.), though such cues may and should be used to determine the beginning and end of divisions
within the text, the distinction between text and notes, etc.
Paragraph breaks should be recorded with <p> in prose and with <lg> (line-group or stanza) in verse.
Record the presence of underlining, bold, and italic text only when it consists of an entire word (or single letter
printed as if it were a word, or a mixed-mode word) or more, and only when you are not using its presence as clue to its structural role.
That is (1) do not place <I>, <B>, or <U> tags around single letters or groups of letters within
words; and (2) as a rule of thumb, if the print mode of the text is being used as a cue to its structural role, do not
record it; if not, do. E.g. a milestone or a heading may sometimes be identified by its bold or underlined text:
record <HEAD> Chapter 3</HEAD>, not <HEAD><B>Chapter 3</B></HEAD>.
 Mixed-mode words (words that contain some letters that are roman, some italic; or some other combination of roman, italic, bold, and underlined) should be recorded as only one of those, the predominant one, Predominance is established not primarily by numerical preponderance, but by context (is the word one of a string of words in italic? If so, it should be treated as italic, even if some of its letters are roman); and by function (are the roman (etc.) letters grouped so that they appear to represent an expansion of an abbreviation? Then the expanded part is not in the predominant mode.).
Mixed-mode words (words that contain some letters that are roman, some italic; or some other combination of roman, italic, bold, and underlined) should be recorded as only one of those, the predominant one, Predominance is established not primarily by numerical preponderance, but by context (is the word one of a string of words in italic? If so, it should be treated as italic, even if some of its letters are roman); and by function (are the roman (etc.) letters grouped so that they appear to represent an expansion of an abbreviation? Then the expanded part is not in the predominant mode.).
Record superscripted and subscripted text with <SUP> and <SUB> tags, regardless of how many characters are involved or where they appear.
5. Recording the apparatus
5.1 Recording the apparatus as <NOTE>
Because of limitations in the content-model of <NOTE>, passages of verse (especially
2 or more lines, quoted and arranged as verse) within a note
will normally be most readily coded as a quotation (<Q>) containing <L>s or <LG>s,
embedded within the <NOTE> element.
Record most apparatus material (marginal and foot notes, etc.) at the point in the main ME text to which it
relates, set off by appropriate tags, not at the point where it appears on the page. If the place is marked in the
text with a flag of some kind (e.g. a footnote reference number, an asterisk (*), etc.), discard this marker both from
the text and from the note. If the note (or similar material) is keyed to the text by line number, place the note at
the end of the line to which it applies, and discard the literal line number from the note.
Use the "PLACE" attribute of the <NOTE> tag to indicate where the note appears on the page:
PLACE="marg" in margin or adjacent to the text
PLACE="foot" in a footnote, below the text
PLACE="end" in an endnote.
PLACE="inline" within the text itself (e.g., in brackets)
PLACE="inter" interlinearly (between the lines of text)
PLACE="head" in a headnote.
If there are multiple distinguishable sets of notes in the same location (two sets of footnotes, for example),
distinguish them by appended numbers: PLACE="foot1" and PLACE="foot2" for example.
A note that spills onto the next page needs to be treated as a single note, not two, and should be placed in the
text where it applies.
Notes and other ancillary apparatus material that relate to a specified group of lines should be moved into the
text at the end of the last line to which they apply, with the line number indication *preserved.* If physical
arrangement, rather than explicit line numbers, serve to specify the line number range, supply the line-number range
in brackets at the beginning of the note. Notes referenced to a line number followed by "f." ("2365 f." meaning "line 2365 and following") should be treated as notes referenced to a span of two lines (in this case, 2365-66), that is, placed at the end of the second line (2366), with the full line reference preserved in the note: <NOTE PLACE="foot">2365 f.: ... </NOTE>
Apparatus that appears next to a single line or set of lines and seems to relate to that line (or set) should be
placed at the end of the line(s) in question.
Notes that apply to two (or more) distinct loci or lines should be reproduced and inserted at *both* (or all) the
relevant points.
Apparatus, such as an introductory headnote, that seems to relate to an entire text division should be attached as
a note to the heading for that division. A summary of the division should usually be given a tag of its own and tagged
as <ARGUMENT>.
Apparatus that relates generally to the material on a page, or for which the appropriate place cannot readily be
determined, should be attached to the last line of text at the bottom of the page.
Multiple apparatus applied to the same locus in the text should be recorded in sequence from from most to least
specific, i.e., e.g.,
(1) apparatus linked by a flag to that precise point;
(2) apparatus linked to that line generally;
(3) aparratus linked to that specific group of lines;
(4) apparatus linked to that area of the text generally.
5.2 Recording the apparatus as <FRONT> and <BACK> matter
Front and back matter will mostly be excluded from keying. When they are included, they are treated much as any
prose in the text is treated: divided and subdivided as necessary into <DIV>s, broken up into paragraphs <
P>, lists <LIST>, tables <TABLE>, etc. A few examples of typical front matter (title pages, tables of
contents, etc.) are included in the appendix, but for the most part you will need to rely on the DTD and TEI
guidelines.
Front matter also includes a special set of elements for the title page (both recto and verso are together coded as
the title page, separated by a <PB> page break). These are a subset of the usual TEI elements, and are used,
together as necessary with <LB> (the line-break tag), chiefly in order to preserve some semblance of the
appearance of the original. Use <LB> tags not for every line break, but only where the line break serves as a
kind of punctuation and is essential to sense. E.g., <TITLE>Three Middle English Romances <LB>Sir Degare,
Sir Launfal, Sir Isumbras</TITLE> (where <LB> marks the beginning of the subtitle).
A typical title page looks like this:
<TITLEPAGE><DOCTITLE>Robert of Brunne's "Handlyng Synne," A.D. 1303, with those parts of the Anglo-French
treatise on which it was founded, William of Wadington's"Manuel des Pechiez,"</DOCTITLE><BYLINE>re-edited
from MSS. in the British Museum and Bodleian Libraries, by Frederick J. Furnivall, M.A. Camb., Hon. Ph.D. Berlin, Hon.
D. Litt. Oxford, Honorary Fellow of Trinity Hall, Cambridge, Founder of the Early English Text and other Societies,
and of the Furnivall Sculling Club.</BYLINE> <IMPRINT><PUBPLACE>London</PUBLACE>: Published
for the Early English Text Society By Kegan Paul, Trench, Trübner & Co., Limited, Paternoster House,
Charing Cross Road, W. C., <DATE>1901</DATE>.<PB> Berlin: Asher & Co., 13, Unter den linden.
New York: C. Scribner & Co.; Leypoldt & Holt. Philadelphia: J. B. Lippincott & Co.</IMPRINT>
<DOCEDITION>Original Series, No. 119.</DOCEDITION></TITLEPAGE>
<DOCEDITION> is used for both edition and series information.
6. Recording the text
(in <DIV> structures, line-groups <LG>, and paragraphs <P>)
A suggested structure will be supplied (by us) with each book, though the data-conversion vendor is free to modify
this if it proves
impractical. Special instructions for tagging the book will be included with the suggested DIV structure.
Decisions about structure are not always clear-cut; complete consistency between the coding of one work and that of
another will be impossible. Consistency *within* a work, however, is essential.
In general, in prose, anything with a true heading is a <DIV> of one level or another (or, in verse, a line-
group). Paragraphs, unless equipped with a heading, are simply <P>. In verse, low-level line groups may be
called <LG>, whether or not they have a heading; <DIV>s should be saved for line-groups big enough to have
titles, or to appear in tables of contents.
At the lowest level, it is often unclear when a group of lines has enough organization to be called a stanza (line-
group <LG>). If in doubt, err on the side of fewer line-groups rather than more. And be consistent throughout a
particular poem, so that a particular structure is not sometimes tagged as a <LG> and sometimes left untagged.
Clues to look at include, in decreasing order of significance:
- Sufficient:
- headings, as above.
- Strongly suggestive:
- blank divider lines.
drop caps
- Indicative, but need support:
- verse structure (rhyme; refrains; etc.)
indentation (but indentation alone is insufficient to justify a <LG> element)
paragraph signs (¶; but these are also used in many cases without any structural function)
A sample suggested/supplied DIV structure (with special instructions) will look like this:
| Text AC = The English Register of Oseney Abbey
Top level
- First <DIV1> = Mirror of the Lyfe of Cryste, pp. [1]-
4.
- This is a fragmentary text containing only the table of contents: tag as a <LIST>
- Second <DIV1> = Oseney Cartulary Englished, pp. 5-209.
- This is the bulk of the book.
Second level Subdivide the second <DIV1>, using:
<DIV2> = the sections denoted editorially by roman numerals and listed in the table of contents on pp. vii-
viii. Use the headings in the table of contents as heading for each section, supplying them within brackets. E.g. <
DIV2 TYPE="Title" N="VI"><HEAD>[VI. Of the Foundation of Oseney]</HEAD> Sometimes the same heading (or
a similar one) is already placed within brackets in the text itself; use the heading from the table of contents and
ignore the bracketed one in the text.
Third level Subdivide all the <DIV2>s, using:
<DIV3> = the sections denoted by arabic numerals.
E.g.
<DIV3 TYPE="ITEM" N="18">
<HEAD>[18.] A Bull of Eugenye pope iij confermyng þe forsaide &yogh;evynges.<
/HEAD>
NOTE: Where <DIV3> breaks coincide with <DIV2> breaks, nest the <DIV3> within the <DIV2>
and apply to each the appropriate heading: <DIV2> gets the roman numeral and chapter heading from the table of
contents, in brackets; <DIV3> gets the arabic numeral and the bold heading printed in the text itself. E.g.: (p.
10):
<DIV2 TYPE="Title" N="VI"><HEAD>[VI. Of the Foundation of Oseney]</HEAD>
<DIV3 TYPE="Item" N="11"><HEAD>[11.] Sequitur ffundacio Oseneye.</HEAD>
<P>HIT is to be know ...
Special instructions for this book.
*Include* the modern English summaries printed in the margins (despite the fact that these are normally excluded
from keying); tag them as <ARGUMENT> and place the <ARGUMENT> tag directly after the <HEAD> at the
head of the item. Many, but not all, of the arguments will begin with a date. Material in square brackets in the
margins is not part of the argument and should be omitted. |
7. Characters
7.1 Special characters
An m-dash should be recorded as — or two hyphens, whichever is easier.
End-of-line hyphens should be recorded with the pipe or vertical bar character (|) = decimal 124 = hex 7C, a
character which should not be used for any other purpose; if the pipe/bar character itself appears on the page,
represent it with an entity reference (|).
Ordinary hyphens in mid-line should be recorded using the regular hyphen character (-).
Decorated characters or large initials should be recorded as if they were ordinary characters; a large decorated
"A" should be recorded as "A".
Small caps should be recorded as regular caps, except where convention and appearance require lower-case, e.g. in
transcribing a title page.
Superscript characters should be treated as small pieces of superscripted text and recorded using the <SUP>
element, not as character entities.
Non-ascii characters should be recorded with SGML character entities, using the standard ISO sets as far as
possible. Standard diacritics (umlaut, acute, etc.) should generally be combined with the character to form a single
entity (ö à é etc.). Macrons above vowels should be recorded with entities ending in
"macr" (ā ō etc.). But macrons above "m", "n", or "p"
should be ignored.
7.2 Representing common characters
Thorn (lower case) : use þ
Thorn (upper case) : use Þ:
Eth (lower case) : use ð
Eth (upper case) : use Ð
Yogh (lower case) : use &yogh;
Yogh (upper case) : use &YOGH;
A-E ligature (lower c.) : use æ
A-E ligature (upper case) : use &AELIG;
Ampersand & tironian "et" : use &
Paragraph/capitulum mark : use ¶
Mid-height dot : use ·
NOTE: There is considerable typographic variety in the printing of some of these characters.
- YOGH: Yogh is especially various: it is especially likely to be confused with a "z" or a "3"
- THORN: Lower-case thorn is often difficult to distinguish from upper-case thorn. Look for several examples
in the same font and compare them in order to establish the contrast between upper and lower case. Some fonts do not
have a upper-case thorn and the same character is used for both. In that case, record the character as lower-case.
- ITALIC YOGH, THORN, etc. Some fonts do not contain italic versions of the yogh or thorn character, and make
the roman character serve instead. Roman-looking thorns and yoghs in predominantly italic text should be treated as italic. This applies only in books that lack an italic thorn, and depends on the definition of "predominantly" used above in §4. It applies mostly to notes, where predominantly italic text is most likely to occur. Following it overliterally in the main text results in the use of <I> tags around words that should not have them, especially þer and þar (occasionally also þus, þou, þys), which are basically normal words with italicized expanded abbreviations (-er -ar -us)--words which should not be treated differently from other words with expanded abbreviations (e.g. "oþer, moþer, furþer"), that is, recorded without italics: þer, þar, þus, þou, oþer, etc.
7.3 Simplifications
| Represent: | as this: |
|---|
| ellipses | "..." (a string of periods) |
| European quotation
marks; inverted quotation marks; baseline quotation marks | " (ordinary quotation marks)
|
| opening & closing
double quotation
marks | " (ordinary quotation marks)
|
| opening & closing
single quotation
marks | ' (ordinary
apostrophe/quot.mark) |
| d with loop or tick | "d" (ordinary d)
(but a barred "d" = ð) |
| f with tick on crossbar | "f" (ordinary f) |
| g with a tick | "g" (ordinary g) |
| k with a tick | "k" (ordinary k) |
| barred-h | "h" (ordinary h) |
| barred-l | "l" (ordinary l) |
| barred-double-l | "ll" (ordinary ll) |
| n with upswept finial | "n" (ordinary n) |
| n with backswept finial | "n" (ordinary n) |
| r with upswept finial | "r" (ordinary r) |
| r with backswept finial | "r" (ordinary r) |
| long-s (see below §7.4.1 for example) | "s" (ordinary s) |
| t with a tick | "t" (ordinary t) |
7.4 Other characters
Other characters and character combinations will turn up. Especially hard to predict are letters combined with some
kind of generic abbreviation symbol. Record these as either an unrecognized character ($x$) or an unrecognized
diacritic ($d$), as appropriate, unless specifically instructed otherwise (in some books you may be told to ignore tilde-like diacritics over consonants). The common abbreviation "Ihc" or "Jhc" (usually with some kind of suspension mark or
macron) should be recorded with the appropriate letters, between dollar signs: $Jhc$ or $Ihc$ or $IHC$ etc.
Similar forms should be similarly recorded, e.g. "Jhu" with abbreviation stroke as "$Jhu$", "Jhus" as "$Jhus$, "Jhm" as $Jhm$, etc.
7.4.1 ADDITIONAL CHARACTERS
The following character instructions were copied from the book-by-book instructions for individual items, June 2000
Record the left-pointing index finger as &lindex;
the right-pointing index fingers as &rindex;
| Double vertical bars should be recorded
with the standard ISO ‖ entity. | 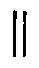 |
| The strange-looking squiggle that appears almost like a little
human figure can be recorded simply by a period (.) | 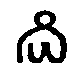 |
| The punctuation mark that looks like an upside-down semicolon ("punctus elevatus")
can be recorded simply with a semicolon (;) | 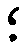 |
| The punctuation mark that looks like an equals sign can be
recorded with an equals sign (=). | 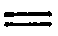 |
| Reversed guillemots | 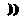 ... ... 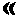 |
| 7-shaped "Tironian 'et'" should be recorded with the ampersand entity (&). this normally appears where one would expect to find an ampersand, between words in the middle of sentences. | 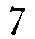 |
| A crossed thorn (which is an abbreviation for "that") should be recorded with the special entity &that; | 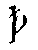 |
| A dotted "y" should be simplified to plain "y" | 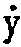 |
| The "long-s" character, should be
recorded simply as "s", but is often very difficult to
distinguish from "f".
|
|
7.5 Punctuation
Punctuation should be retained, including the virgule, period, or mid-line dot marking the caesura or midpoint of a
verse line. See also the comments on hyphens above under 7.1.
Strings of dots or asterisks indicating omitted or missing text should be recorded as five of that character in
ordinary text, using periods or asterisks separated by spaces: . . . . . * * * * *
Verse lines consisting only of dots (.....), which are numbered as part of the verse, should be treated as lines containing only dots (<L> . . . . . </L>)
Some editions of prose mark extended quotations by placing
quotation marks at the beginning of every line. E.g.,
he made reasons...seyenge:
" God made alle thynges by reason, and governethe thynges
" made by reason; the sterres be movede by reason; and so
" oure naturalle lyfe excedynge from reason by slawthe and
" ignoraunce awe to be reducede by lawes and reasons.
" Wherefore thau&yogh;he there be somme thnges in the rule of
" seynte Benedicte, the intellect of whom the dullenesse of my
" mynde may not comprehende, y suppose hit be beste to &yogh;iffe
" credence to auctorite;
This is OK in verse, but in prose, separated from the printed page, without line breaks, these
make no sense. When blocks of
beginning-of-line quotation marks occur, EITHER: (1)
*include them* but include a <LB> tag too (<LB>"God made alle thynges);
or
*include them* but record them with a special character
entity; whichever is easier.
7.6 Illegible/indecipherable text
- If a word is illegible, record it as $word$
- If an entire line is illegible, record it as $line$
- If a character is not recognized and cannot be recorded, as required above, with a character entity,
record it as $x$
- If a diacritic is not recognized as a standard one, record it as $d$